在V8环境下,++i与i++ 的具体实现过程
补充3:
谢谢大家的热情回答~!
通过
md5ryan
与
2bdenny
l两位以及
之前多位
的回答,已经可以给在C中这两者的效率问题盖棺定论了。
在早些时候应该是前置递增比较的有效率,而在
现代
两者已经
没有区别
了。
不过LZ其实想问的是在
JS
中这两者的效率有米差别囧。。。。。。
在C中可以通过查看其汇编后的代码来分析两者有没有差别,不过在像JS这种解释性语言要怎么分析这种类型的问题呢??
想了想大致可以分为两种方法吧:
1、实验法,就是分别写一段代码,测试时间
2、分析其引擎实现,像JS的话就是指的是V8
第一种方法简单易实现,不过还是从表面观察,有种雾里看花的感觉
第二种方法很难,因为这是要去掌握规则,不过一旦掌握了,按照一般奇幻小说里的等级构架那就是传奇法师级别的了吧~~
我辈的追求大概就是不断的去寻求真理吧!
所以
问题更新
了~
在
V8
环境下,++i与i++ 的具体实现过程
LZ能力有限,在这提供给大家V8在GitHub上的源码镜像 https://github.com/v8/v8
原问题
:
for (var i = 0; i < N ; ++i)中 ++i 而不是 i++ ,是不是只是习惯的上的区别??
补充2:
首先!
我真的
不是
在问前置递增与后置递增的区别!!,汗。
注意下上下文,是在
for这表达式
中这两者有没有区别!!!
比如
效率
上两者有没有差距,等
明白i++与++i的区别,但在for循环应用中有点迷惑。
for (var i = 0; i < 10; i++) {
print(i);
}
for (var i = 0; i < 10; ++i) {
print(i);
}
输出的都一样:0~9
补充1:
额,好像大家有点理解错我的意思了。。。
被踩那么多,好郁闷啊。。。。
今天看书的时候,看到作者是这样写的
for (var i = 0; i < this.dataStore.length; ++i)
但平时自己习惯是写
i++
的,后来查了下书,这应该等价于
var i = 0
while (i < this.dataStore.length){
code
++i
}
和
var i = 0
while (i < this.dataStore.length){
code
i++
}
这样不管是先运算i,还是后运算i的值,最后都是一样的吧。因为已经不会影响到code里的代码了。
所以这样
for (var i = 0; i < this.dataStore.length; ++i)
中
++i
的写法只是习惯问题吧??
或者会有其他什么影响吗??
我想问的是这个,可能有些人理解为我问
++i
与
i++
的区别的吧,囧。
Answers
下面是 ++ 和 -- 的前缀实现形式:
T& T::operator++(){
++*this;
return *this;
}
下面是 ++ 和 -- 的后缀实现形式:
T T::operator++(int){
T old(*this);
++*this;
return old;
}
我们来分析一下自增自减的后缀形式所多花费的开销:
T old(*this);
这 一句产生一个类型为T的临时对象 old, 并用原值*this进行初始化.当函数return的时候,又再次创建一个临时对象,并用old的值进行初始,之后,局部变量old被销毁.并用临时创建 的变量对赋值符左边的变量进行赋值(如果有的话).赋值后,临时变量再次被销毁.
而前缀形式的自增自减呢?首先函数内没有创建临时变量,故这方面的开销就节省了.其次,返回的是一个引用,故也节省了这时候创建销毁临时对象的开销.
因此后缀式的自增自减,所多花费的开销是两次临时变量的创建,以及两次临时变量的销毁.如果自增自减的对象不是内建的数据类型,而一个类类型[当然,你首 先得重载自增自减操作符:) ], 那么这个开销可能会比较大.因为变成了两次构造函数以及两次析构函数的调用.
所以在调用代码的时候,要 优先使用前缀形式,除非确实需要后缀形式返回原值.
i++是先返回值再自增,++i是先自增再返回值。
嗯。举个例子
//i++的例子
function fn(){
var i = 0;
return function innerFn(){
alert(i++;)
}
}
var test = fn();
test();//0,i++先返回0,再自增
test();//1,上一次调用i自增了1,所以此时返回1,再自增
//++i的例子
function fn(){
var i = 0;
return function innerFn(){
alert(++i;)
}
}
var test = fn();
test();//1,先自增再返回值
test();//2
TZ, 我帮你试了
首先这是第一段测试代码:
#include <stdio.h>
int main(){
int k = 0, i;
for (i = 0; i < 10; ++i) k += i;
printf("%d\n", k);
return 0;
}
这段代码生成的汇编代码是:(放在文件try1.s里)
.file "try.c"
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "%d\12\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
LFB6:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
call ___main
movl $0, 28(%esp)
movl $0, 24(%esp)
jmp L2
L3:
movl 24(%esp), %eax
addl %eax, 28(%esp)
incl 24(%esp)
L2:
cmpl $9, 24(%esp)
jle L3
movl 28(%esp), %eax
movl %eax, 4(%esp)
movl $LC0, (%esp)
call _printf
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
LFE6:
.def _printf; .scl 2; .type 32; .endef
然后我又照着你的意思改了下测试代码,变成后缀式:
#include <stdio.h>
int main(){
int k = 0, i;
for (i = 0; i < 10; i++) k += i;
printf("%d\n", k);
return 0;
}
然后生成了新的汇编代码:(放在文件try.s里面)
.file "try.c"
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "%d\12\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
LFB6:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
call ___main
movl $0, 28(%esp)
movl $0, 24(%esp)
jmp L2
L3:
movl 24(%esp), %eax
addl %eax, 28(%esp)
incl 24(%esp)
L2:
cmpl $9, 24(%esp)
jle L3
movl 28(%esp), %eax
movl %eax, 4(%esp)
movl $LC0, (%esp)
call _printf
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
LFE6:
.def _printf; .scl 2; .type 32; .endef
为了方便对比,我索性帮你对比了:
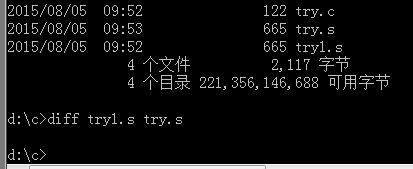
没有任何输出就是说两者汇编代码完全一样的意思, 解答TZ的疑问了吗:-)?
楼上各种说不一样的, 我就静静地看着你们装逼. 别的编译器我不说, 你用gcc编译器会对你写的代码进行优化的, 你自己也可以通过-O1 -O2 -O3来控制, 你们先来一发测试再说.
talk is cheap, show u the code.
int main(void)
{
int num = 0;
for (int i = 0; i < 5; ++ i)
{
num = num + 1;
}
return 0;
}
用 gcc -O3 test.c -o test 然后改为后加再编译为test2, 自己用diff去比较去;
编译为汇编代码也是一样的...
你问的应该不是语义的区别,那么就谈关于效率吧:
首先回答你的问题, 在JavaScript这类高级编程语言和任何拥有现代编译器的语言中,效率没有区别!
在面向对象的编程语言中,前自增和后自增的区别在于后者需要拷贝返回值,多一次拷贝构造函数调用。
因为返回的对象是自增之前的,已经不是当前变量了,显然要把它存起来再返回。举例来讲:
Obj operator++(Obj& rhs, int i){
Obj ret = rhs;
rhs.x ++;
return ret;
}
在
rhs.x
自增之前需要保存一份原有对象作为
ret
,用来返回。如果是前自增,便不需要保存这一份。所以C++中仍然有面试官上来就问前自增后自增的区别!fuck it!讲编程习惯的可以不必理他,编译器会帮你优化,而你能做的最好的事就是提高可读性,显然后自增更好。
C++中自增运算符的重载可以参考: http://harttle.github.io/2015/06/25/operator-overload.html
然而,你的for循环里并未对它取值,多数编译器都会把它优化掉,不再拷贝一份(即使是C++)。对于像JavaScript这类语言更不需要考虑这个问题!更常见的效率损失在于不合理的网络请求、不需要的DOM操作、页面重绘和回流。