为什么Boost库的搜索函数明显比std的search慢
在学习boost的时候测试了一下boost的algorithm中的三个search函数,分别是Boyer-Moore Search,Boyer-Moore-Horspool Search,Knuth-Morris-Pratt Search,同时也测试了std的search函数,测试的结果有点意外,std的search花的时间比前面三个快了两个数量级,问题出在哪儿?测试的代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <boost/algorithm/searching/boyer_moore.hpp>
#include <boost/algorithm/searching/boyer_moore_horspool.hpp>
#include <boost\algorithm\searching\knuth_morris_pratt.hpp>
#include <string>
#include <vector>
#include <algorithm>
#include <iostream>
#include <Windows.h>
#include <time.h>
using namespace std;
using namespace boost::algorithm;
void printMessage(char* msg, int startX, int startY)
{
HANDLE hd;
COORD pos;
pos.X = startX;
pos.Y = startY;
hd = GetStdHandle(STD_OUTPUT_HANDLE);
SetConsoleCursorPosition(hd, pos);
printf("%s", msg);
}
int main(int argc, char ** argv)
{
printf("Generating test set\n");
vector<int> vec;
srand(unsigned int(time(NULL)));
for (int i = 0; i < 10000; i++)
{
vec.push_back(rand() % 15000);
char msg[50];
sprintf(msg,"%.2f%%\n", i*1.0/99.99);
printMessage(msg, 0, 1);
}
LARGE_INTEGER t1, t2, tc;
QueryPerformanceFrequency(&tc);
QueryPerformanceCounter(&t1);
printf("Testing boyer moore search\n");
int count = 0;
for (int i = 0; i < 1000; i++)
{
vector<int> key;
key.push_back(rand() % 15000);
if (boyer_moore_search(vec.begin(), vec.end(), key.begin(), key.end()) != vec.end())
{
count++;
}
char msg[50];
sprintf(msg,"%.2f%%\n", i / 9.99);
printMessage(msg, 0, 3);
}
cout << "Hit " << count << "times\n";
QueryPerformanceCounter(&t2);
printf("Costing time: %.2f s\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart);
system("pause");
QueryPerformanceCounter(&t1);
printf("Testing boyer_moore_horspool search\n");
count = 0;
for (int i = 0; i < 1000; i++)
{
vector<int> key;
key.push_back(rand() % 15000);
if (boyer_moore_horspool_search(vec.begin(), vec.end(), key.begin(), key.end()) != vec.end())
{
count++;
}
char msg[50];
sprintf(msg, "%.2f%%\n", i / 9.99);
printMessage(msg, 0, 8);
}
cout << "Hit " << count << "times\n";
QueryPerformanceCounter(&t2);
printf("Costing time: %.2f s\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart);
system("pause");
QueryPerformanceCounter(&t1);
printf("Testing knuth_morris_pratt search\n");
count = 0;
for (int i = 0; i < 1000; i++)
{
vector<int> key;
key.push_back(rand() % 15000);
if (knuth_morris_pratt_search(vec.begin(), vec.end(), key.begin(), key.end()) != vec.end())
{
count++;
}
char msg[50];
sprintf(msg, "%.2f%%\n", i/ 9.99);
printMessage(msg, 0, 13);
}
cout << "Hit " << count << "times\n";
QueryPerformanceCounter(&t2);
printf("Costing time: %.2f s\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart);
system("pause");
QueryPerformanceCounter(&t1);
printf("Tesing std search\n");
count = 0;
for (int i = 0; i < 1000; i++)
{
vector<int> key;
key.push_back(rand() % 15000);
if (search(vec.begin(), vec.end(), key.begin(), key.end()) != vec.end())
{
count++;
}
char msg[50];
sprintf(msg, "%.2f%%\n", i/ 9.99);
printMessage(msg, 0, 18);
}
cout << "Hit " << count << "times\n";
QueryPerformanceCounter(&t2);
printf("Costing time: %.2f s\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart);
system("pause");
return 0;
}
测试环境是vs2013,测试结果如下图:
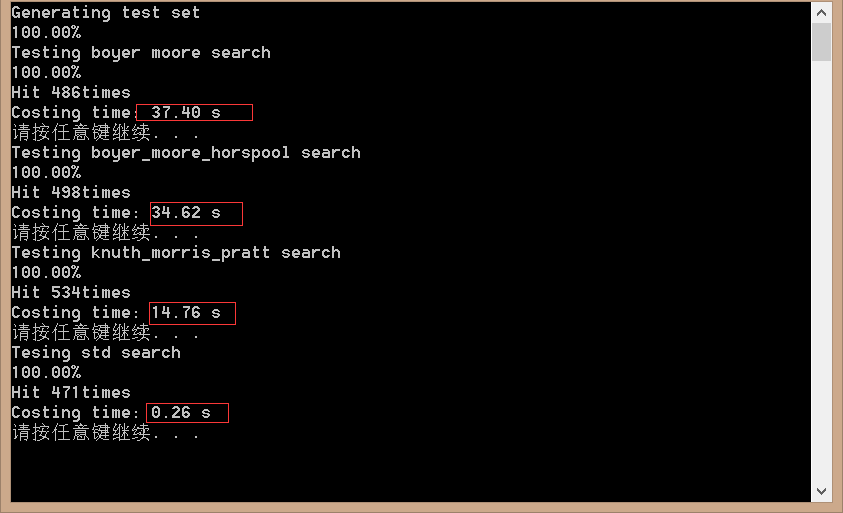
是什么导致了这么大的差距?
Answers
问题在于几次测试所用的源串相同,但目标串不同;应该保证几次的测试的目标串也相同,才能比较算法本身的差异(“控制变量法”)。
比如暴力法串匹配:
pythondef search(source, target): for si in range(len(source)): for ti in range(len(target)): if si + ti >= len(source) or source[si+ti] != target[ti]: break if ti == len(target)-1: return si return -1
最坏情况下的时间复杂度是O(mn), 其中m, n分别是source, target串长度,比如有两个字符串:
source: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab
target: aaaaab
这种情况就会是O(mn)的复杂度,但如果target是:baaaaa
则是O(m)。
可以把程序的key填充放到vec填充的循环里去,都是随机数没什么关系,当然也可以单独用一个循环。
个人认为,单纯用随机数做source和target串,几个算法的表现都会接近O(m);若想凸显几个算法的复杂度差异,可以针对具体算法实现构造特殊case(如上面的source, target特例就是根据暴力法的具体实现构造的)