python html 标签剔除
例如
【11月25日 AFP】バラク・オバマ(<a href=\"http://www.afpbb.com/search?fulltext=Barack%20Obama&category%5B%5D=AFPBB>%E8%A8%98%E4%BA%8B&category%5B%5D=%E3%83%AF%E3%83%BC%E3%83%AB%E3%83%89%E3%82%AB%E3%83%83%E3%83%97&category%5B%5D=%E4%BA%94%E8%BC%AA\">Barack Obama</a>)米大統領は24日
期待抽取结果是:
AFP】バラク・オバマ(Barack Obama)米大統領は24日
_EXTRA_HTML_TAGS_RE = re.compile(r'<(\/)?(a|b).*?>', re.IGNORECASE)
text = = _EXTRA_HTML_TAGS_RE.sub('', text)
实际结果为:
AFP】バラク・オバマ(%E8%A8%98%E4%BA%8B&category%5B%5D=%E3%83%AF%E3%83%BC%E3%83%AB%E3%83%89%E3%82%AB%E3%83%83%E3%83%97&category%5B%5D=%E4%BA%94%E8%BC%AA">Barack Obama)米大統
链接里的>影响了正则匹配,如何写这个正则才能达到预期输出结果,同时,又满足之前的功能
Answers
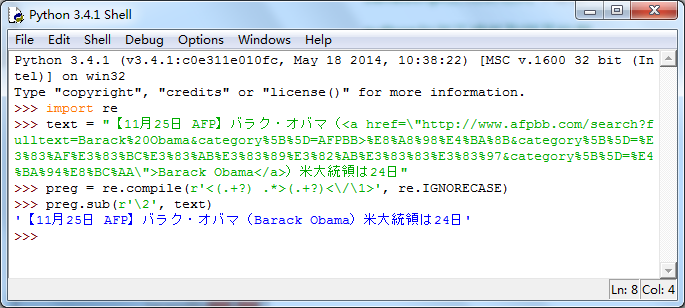
preg = re.compile(r'<(.+?) .*>(.+?)<\/\1>', re.IGNORECASE)
preg.sub(r'\2', text)
不过推荐还是用专门的HTML解析工具去做这件事,随便搜到一个就顺手推荐一下叻: http://old.zope.org/Members/chrisw/StripOGram/readme/
